
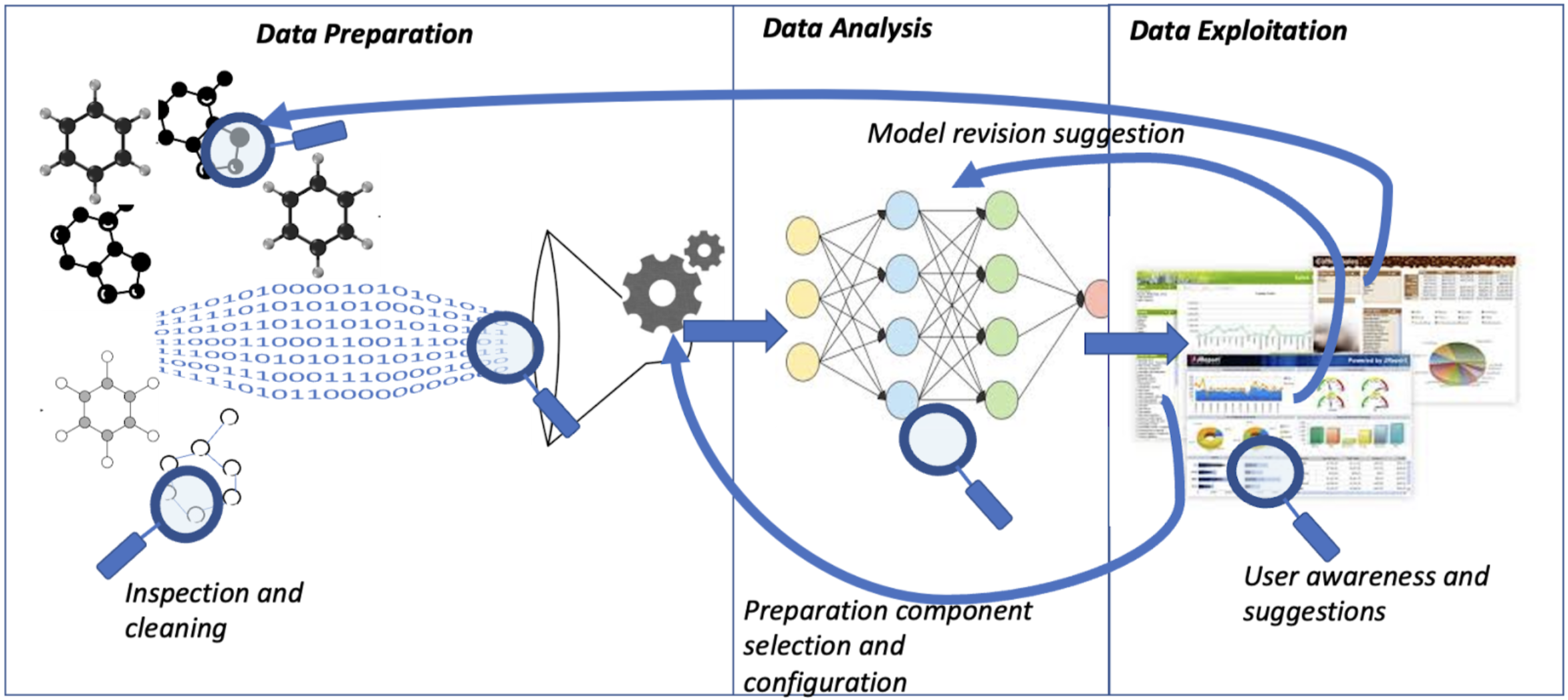
As illustrated in the figure, the project proposes a discount quality and sustainable support for the data science life cycle which consists of the following three phases:
Data Preparation : results of data-driven experiments depend on the predictive models, but also, and significantly, on the data prepared to generate the results: on their quality (e.g., missing values), their semantic features (e.g., type of objects and measures described in the data, relationships, value distributions, etc.). Data preparation pipelines may orchestrate different operations on the data, such as discovery and acquisition from repositories, curation and quality improvement, integration, and enrichment. Support in this phase will be the main goal of the project. In particular, we plan to study how to focus the users’ effort on the portion of the data that mostly affects the quality of the data for their task at hand (i.e., task-driven data preparation). This is possible by taking into account in a unified framework: (i) the benefit of preparing and cleaning a certain portion of data based on the users’ information needs and the quality level that they require for trustworthy results; (ii) the effort (e.g., human time and computational resources) required by that preparation on that data.
Feedback from subsequent phases will also be considered to refine the preparation process and evaluate the impact on them. High-effort and low-effectiveness data preparation tasks should be reduced to the benefit of low effort and high impact on the results activities. In the preparation, inspection, and reuse of data curated by third parties or in previous analysis has to be considered, which requires data search and discovery capabilities. Since manually curated metadata may be insufficient to support this discovery process because they boost the terminological entropy, and require tedious and cost-intensive annotation processes, we focus on solutions for the automatic semantic annotation of data using reference vocabularies (e.g., with Schema.org or more domain-specific vocabularies) and their revision in a HITL fashion, ultimately producing richer profiles at limited costs. Ultimately, semantic annotation of data sources will produce content-based data profiles. For this profiling activity, we plan to combine approaches for the semantic interpretation and annotation of tabular and similar data, e.g., CSV and JSON to natively profile these kinds of data, also in compliance with recently proposed standards (e.g., W3C’s Tabular Metadata) – already processed by data search engines. In particular, we plan to focus on the semantics of numerical attributes by exploring novel representation-learning approaches to learn succinct representations of data elements for existing sources, eventually used to suggest semantic labels for new data.
In addition, a balance must be pursued in data preparation between HITL activities and benefits deriving from the application of automated techniques.
WP1 Reference Models and Architectures for Interpretable Pipelines
In this WP, we will study reference models for ensuring interoperability across the loop, encompassing metadata and data annotations, pipeline specification and execution frameworks, data quality and visual exploration frameworks. The following tasks will be developed:
- State of the art and requirements. In this task, we will update the review of state-of-art approaches that can contribute to support the target human-centered loops for specification and execution of pipelines, drawing requirements that must satisfied to ensure interoperability within and outside the project (e.g., in compliance with existing standards and recommendations).
- Reference models. Informed by the previous analysis, this task proceeds by selecting reference models to comply with and a reference architecture to support the interaction among components that are used in the following development of the project.
WP2 Data Preparation and profiling
In this WP we develop methods for data preparation combining algorithmic intelligence and users’ actions to support the preparation of the data for an experiment, its profiling, and its refinement to improve models and results. By tracking these processes we also learn how to better prepare, profile and refine data across multiple experiments. In fact, preparation for a
current experiment is informed by actions/results from previous similar experiments. Two tasks are to be developed in this WP:
- Content-based Profiling: In this task, we will develop methods to support semiautomatic production of profiles of data sources, in such a way to foster downstream data search and reuse, with a focus on profiling aspects not covered by state of the art approaches, i.e., especially, semantic profiles based on the annotation of existing data sources with relevant vocabularies and statistics. We first fine-tune algorithms for semantic interpretation of semistructured data sources and then design the HITL revision process, which can be supported by in-house interactive applications. Finally, we will make sure that annotations comply with formats and vocabulary recommended by international bodies (e.g., using the Schema.org vocabulary and the metadata vocabulary for tabular data defined in https://www.w3.org/TR/tabular-metadata/ )
- Task-driven data preparation: We first set up a state-of-the-art framework for the specification and execution of data preparation to support HITL mechanisms, starting from the tools considered in the literature. We then investigate the problem of task-driven data preparation, where the users are guided on selecting the proper data preparation operators and on which data to focus on to maximize the quality of the data for their tasks at hand—not all the tasks require the same quality level, and most of the time each task is focusing only on a portion of the data. That is possible by modeling and implementing a cost-benefit model for the data preparation operators and by adapting active learning techniques when ML is involved in the process.
WP3 Data Quality
Assessing the quality of the data during and after preprocessing is a complex and time-consuming activity. On the other hand, a better quality guarantees better results in the analysis of data and in the development of machine learning models reducing the overall uncertainty. In addition, evaluating the quality of data avoids performing heavy ML training and analysis tasks on poor quality data and therefore with poor outcomes.
The WP focuses on two specific tasks:
- Sustainable Data Quality assessment: in this task, we aim to define techniques for a rapid assessment of data quality, at all stages. Traditional data quality assessment techniques are indeed time and resource consuming activities. In the literature, random sampling techniques are often used for decreasing the processing space and time, but such an approach does not guarantee the representativeness of the sample and thus the reliability of the assessment process. Exploiting semantic annotation and profiling metadata, more advanced techniques can be designed in order to gather the relevant quality issues and better drive the data preparation in order to minimize the uncertainty that might affect the final results.
- Data Quality annotations: in this task we aim to develop methods for associating context-related quality information to data in order to favor their reusability and to avoid repeating data quality assessment operations when reusing data. The availability of data quality annotations allows users to get a hint about the trustworthiness and the suitability of the data source for the task at hand.
In summary, we provide a conceptual model for classifying and annotating the datasets resulting from data preparation pipeline with quality and performance information. The generation of metadata related to the processing tasks has been recognized as essential for enabling data reusability. The annotations are intended to provide the designer with preliminary information on the expected quality of a dataset after preparation tasks in a context-aware manner. To this aim, the dataset resulting from the application of the pipeline is automatically annotated with provenance metadata for a detailed pipeline description. The metadata is generated with HITL techniques, balancing automatic data quality assessment methods and human annotations on selected samples. A cost-benefit assessment model will be proposed, to identify when and where human intervention is needed, after the requirements for the context being considered are defined.
WP4 Information visualization and visual analytics
Exploratory Data Analysis is a task involving the Human and usually supported by disciplines such as Information Visualization, Visual Analytics and Human-Computer Interaction. However, as data to explore increases in size and dimensionality, the capability to still support exploratory tasks is hindered due to the rise of latency effects, as well summarized in [Liu14]. When coping with this problem, the trend is to run a large number of simulations in a batch, wait for the result, analyze it and repeat. While presented with the result of the batch, users could have the need to explore data by interacting with a visual interface to assess its validity. In such a situation, having a non-optimized interface that introduces latency in the interaction could make the data exploration not feasible, affecting its efficacy. To mitigate this problem we propose to build an intelligence layer driving the Visual Analytics interface used for evaluating the experiments that semi-automatically model user behavior while exploring data through a web based visual interface, leveraging labeled statecharts of its main interactors (i.e., modeling the transitions between states of an interactor, like a slider, to monitor at any moment which subsets of user interactions can happen after the current one) used for exploring the data at hand (e.g., both UI means like a slider and direct manipulation of the visualization like a brushing operation). Through an automated exploration of the obtained statechart, we identify critical spots in which the interaction suffers from latency issues (measurement and monitoring of the introduced latency); we then use the modeled dynamic latency to inform two different optimizers:
- The first one is based on exploiting the collected information from user interactions through the visual interface and exploiting them to predict what the user will do next (or identify recurring analysis patterns) and prefetch specific data when needed, allowing the reduction of the perceived latency in exploration (e.g., prioritizing visual areas where the user interacts the most or data tuples based on interesting sub-intervals).
- We pair this layer with human-centered progressive visualization techniques: it allows smartly creating a succession of data visualizations that converges toward the exact one, leveraging chunking the dataset, sampling the dataset, or using approximated versions of analysis algorithms (e.g., progressive t-SNE [Pezzotti17]) to allow keeping the latency of user exploration under a predetermined threshold. These two optimizers effectively enable the human-in-the-loop paradigm, anticipating the user interaction with the simulation results with respect to a long-lasting simulation and allows her to explore its results effectively and understanding if the simulation/experiment is leading towards good results, confirming its execution to the final stage, or not, pruning it and focusing on the next interesting simulation. In this way this whole approach allows reaching the sustainable and responsible data science goal in terms of effective usage of computation resources and human involvement.
